AI tạo sinh của Apple (được gọi là Apple Intelligence) có thể ra mắt muộn hơn nhiều so với các đối thủ phổ biến khác như ChatGPT, Llama, nhưng đang tỏ ra thắng thế trên khá nhiều phương diện. Một sách trắng về mô hình LLM Apple's Foundation Model (AFM) do công ty tự phát triển, hỗ trợ cho Apple Intelligence, tiết lộ 2 thông tin quan trọng: Đầu tiên, đây là mô hình an toàn nhất về mặt thiết kế, và thứ hai là nó có khả năng cạnh tranh cao với cả Llama của Meta và GPT-4 của OpenAI.
Trong các bài kiểm tra, AFM có khả năng viết và tóm tắt ngang bằng với LLM hàng đầu của OpenAI, Meta, Mistral AI và các công ty khác. Nhờ các hướng dẫn nghiêm ngặt của Apple về việc xóa nội dung có hại, các bài kiểm tra do con người đánh giá liên tục xếp hạng mô hình AFM là an toàn nhất so với tất cả các mô hình còn lại với biên độ lớn.
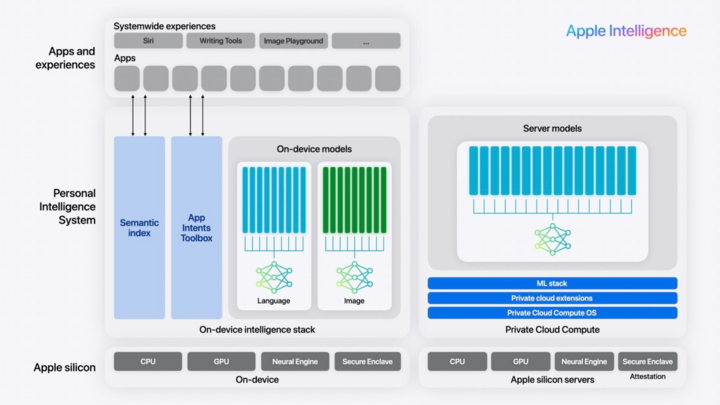
Sơ đồ cấu trúc AI của Apple.
Dữ liệu và tương tác của người dùng được xử lý thông qua hệ thống AI ngay trên thiết bị, sử dụng chip silicon của Apple để đảm bảo hoạt động nhanh chóng, riêng tư và an toàn. Các tác vụ tốn nhiều tài nguyên hơn hoặc những tác vụ yêu cầu bộ dữ liệu lớn được gửi đến cơ sở hạ tầng điện toán đám mây riêng, hỗ trợ cho các mô hình trên thiết bị và mở rộng khả năng của chúng mà không ảnh hưởng đến quyền riêng tư.
Hồi giữa năm, Apple đã gây sốt khi trình diễn Siri tích hợp với ChatGPT tại hội nghị lập trình viên WWDC thường niên. Điều này khiến nhiều người cho rằng OpenAI đứng sau toàn bộ Apple Intelligence, nhưng thực tế không phải vậy.
Apple Intelligence là một thuật ngữ marketing, gắn nhãn cho một loạt các tính năng AI mới. Nó sẽ có trên mọi nền tảng Phần mềm chính, từ iOS, iPadOS cho đến macOS.
Có thể suy đoán, OpenAI và ChatGPT chỉ hỗ trợ Siri, còn mô hình AFM mới thực sự là module cho Apple Intelligence. Mô hình AFM đối với Apple Intelligence giống như GPT-4 đối với ChatGPT, Whisper và các dịch vụ AI khác. Nói cách khác, năng lực của mô hình AFM sẽ liên quan trực tiếp đến năng lực tất cả các tính năng Apple Intelligence.
Sách trắng khoa học do hơn 150 nhân viên của Apple biên soạn đã phác thảo rất chi tiết về quá trình đào tạo, hiệu suất và đánh giá của mô hình AFM.
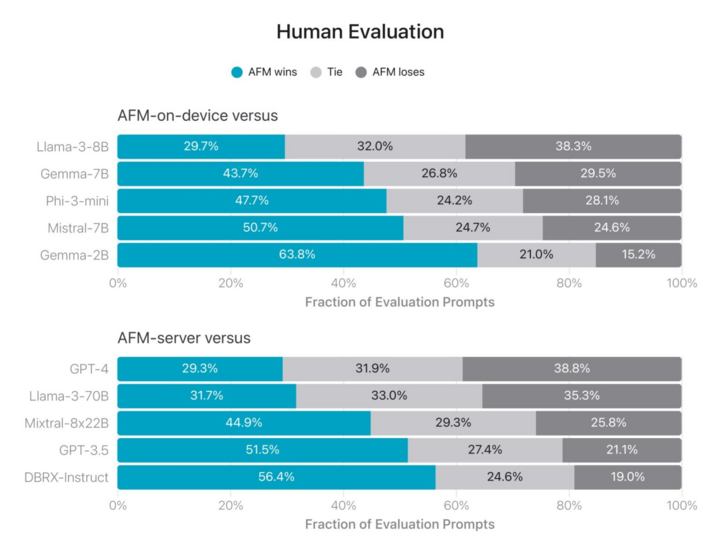
Kết quả các bài kiểm tra so sánh AFM với các mô hình khác do con người thực hiện. Màu xanh là tỷ lệ AFM chiến thắng, màu xám nhạt là hòa và xám đậm là thua.
Trong thử nghiệm đánh giá của con người, 1.393 prompt được đưa vào mô hình AFM và đối thủ. Nó đã được thử nghiệm riêng biệt với các LLM nguồn mở hàng đầu chạy trên thiết bị và LLM thương mại chạy trên đám mây.
Dù là chạy trên thiết bị hay trên đám mây, kết quả khá tương đồng. So với Llama-3 và GPT-4 mới nhất và tiên tiến nhất, AFM tụt lại phía sau một chút. So với các đối thủ còn lại, AFM tỏ ra độ vượt trội, vượt xa GPT 3.5 hay Mistral.

Kết quả kiểm tra năng lực tóm tắt và viết văn bản của AFM so với các đối thủ.
Về năng lực tóm tắt, khi chạy trên thiết bị, AFM đứng số 1, còn với soạn thảo văn bản thì chỉ thua một chút so với Mistral hay Gemma. Trong khi đó, năng lực của server cho thấy AFM vẫn đứng đầu về khả năng tóm tắt, cũng suýt soát GPT-4 về khả năng soạn thảo.
Nhưng phần kiểm tra tiếp theo mới cho thấy thế mạnh thực sự mà AFM bỏ xa đối thủ, đó là độ an toàn của nội dung tạo sinh do con người đánh giá.
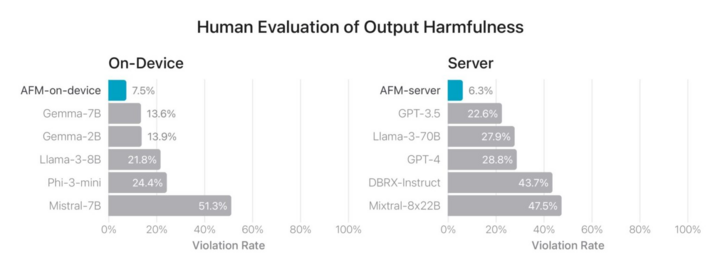
Đánh giá mức độ gây hại trong đầu ra của mỗi mô hình - Apple ở mức thấp nhất, bỏ rất xa các đối thủ còn lại.
Với 9 trong số 10 bài kiểm tra do con người đánh giá, kết quả đầu ra từ mô hình AFM được coi là an toàn hơn trong 50% số lần. Trong tất cả 10 bài kiểm tra, kết quả này hòa chiếm 23% số lần.
Apple đã loại bỏ nghiêm ngặt nội dung có hại khỏi dữ liệu đào tạo của mình. Theo sách trắng, dữ liệu đầu vào trải qua "lọc chất lượng sâu rộng" để đảm bảo an toàn và không thô tục, "sử dụng phương pháp tìm kiếm và phân loại dựa trên mô hình". Việc thanh lọc dữ liệu đào tạo có tác động rất lớn đến kết quả đầu ra của mô hình.
Những đối thủ khác trong lĩnh vực này đã bị chỉ trích nặng nề vì đào tạo AI của họ bằng video YouTube, mọi thứ trên Reddit và toàn bộ internet mà không qua sàng lọc kỹ lưỡng.
Trong các bài kiểm tra benchmark, AFM cũng cho kết quả khá tốt, với việc AFM thường xuyên đứng đầu. Tuy nhiên, hiệu suất của AFM trên thiết bị có phần chưa bằng một số đối thủ, nên đây là nơi Apple cần cải thiện nhiều.
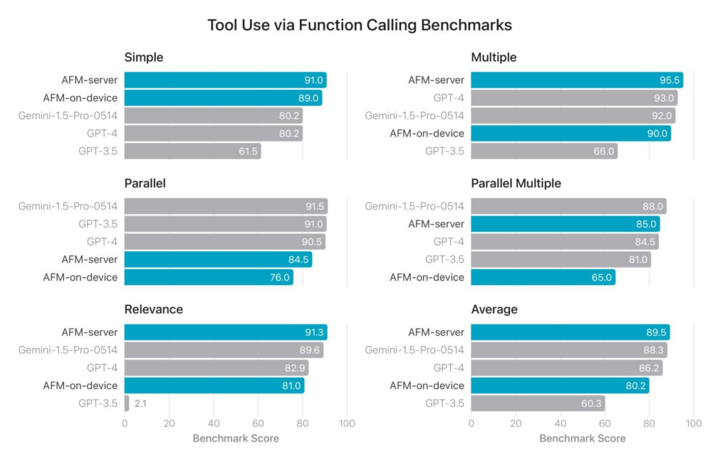
Kiểm tra benchmark bằng một số công cụ AI thông qua việc gọi hàm.
Phiên bản beta mới nhất của iOS 18.1 và macOS Sequoia 15.1 chỉ có các công cụ viết và chỉnh sửa hình ảnh, nhưng sẽ sớm sở hữu nhiều tính năng hơn nữa. Trong bản phát hành trong tương lai, Siri sẽ có thể hiểu các ứng dụng trên điện thoại của người dùng, thực hiện các lệnh bằng ngôn ngữ đơn giản. Kết quả kiểm tra độ hiệu quả của tính năng này có thể được thấy trong benchmark trên, mục Simple.















